前回はPower Query(パワークエリ)のカスタム関数の作成事例として、単票形式のExcelシートからセルの値を抽出する方法を紹介しました。今回は列のピボット解除などを活用して、同様にセルの値を抽出する方法の備忘録。
個人的な結論として、カスタム関数の利用と比較すると、手順の難易度が低いという印象。
なお、使用のExcelは、Microsoft® Excel® for Microsoft 365 MSOです。
内容:
前提
前回と同様、単票形式のExcelシートをPower Queryで読み込み、テーブルからセルの値を取得したい。詳細は以下を確認ください。
参考にした情報
Power Queryでセルの値取得の考え方等は以下の解法2を参考にさせていただきました。
以下は、上記の考え方を参考にさせていただき、フォルダの指定と、Table.AddIndexColumn関数を活用した場合の手順です。
手順
データ取得のフォルダを指定し、「データの結合と変換」のクリック
「データ」タブにて、「データの取得」-「ファイルから」-「フォルダから」の順にクリック後、「データの結合と変換」をクリックする。
「データの結合と変換」の詳細が不明な場合は以下も参考にしてください。
上記実行すると、次のように複数のExcelシートが結合され、そのままテーブル化される。ただし、項目ごとの一覧形式ではなく単票形式のExcelシートがテーブル化されただけで、集計等が困難な状態。
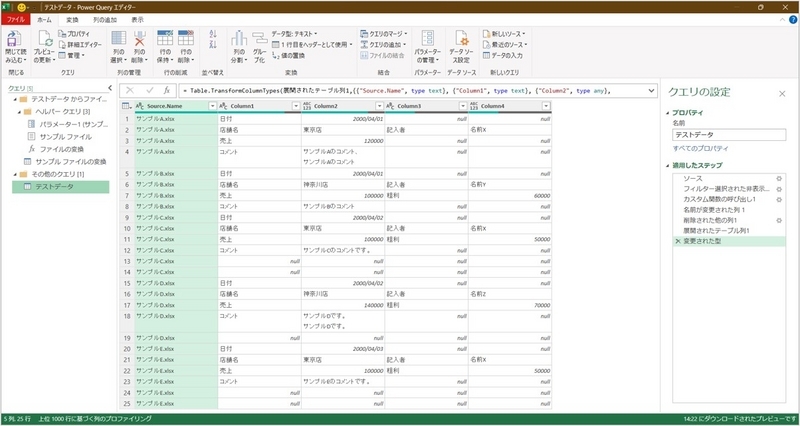
なお、上記画面のとおり、「Souce.Name」のフィールドに取得したファイル名がある。Excelシートのセル位置を取得するために、「行位置」に関する情報をファイル名ごと付与したい。
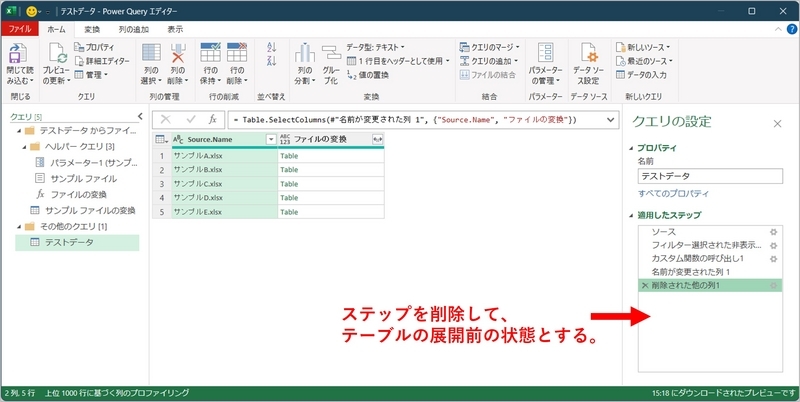
テーブルの展開前の状態まで、ステップを削除
「適用したステップ」で、テーブルの展開前の状態(各ファイルを取得した状態)まで、ステップを削除する。
目的は、行位置に関する情報をファイル名ごとに付与するため。フォルダ指定によるデータ取得の設定は残してTable.AddIndexColumn関数を設定する手順が効率的と思われる。
「カスタム列」で行位置を追加
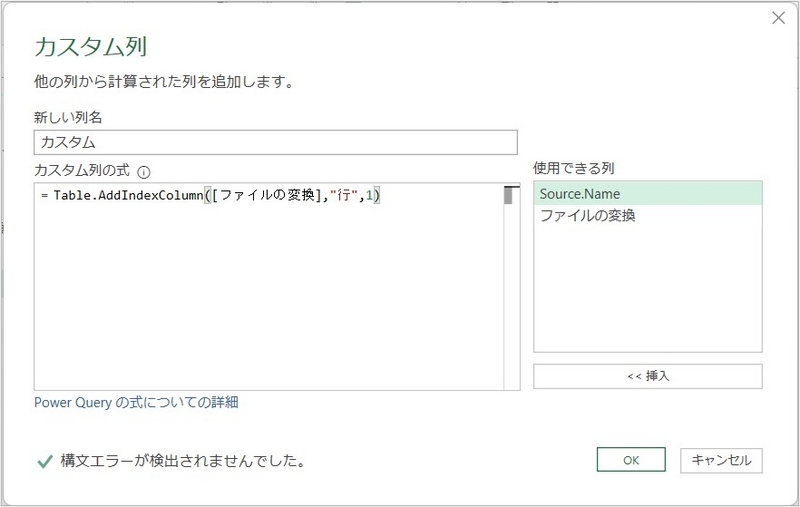
各ファイル毎のTableに対して行位置の追加は、Table.AddIndexColumn関数で可能。
事例では、「ファイルの変換」フィールドにTableがある。
Table.AddIndexColumn([ファイルの変換],"行",1)
とすることで、Tableに「行」というタイトルで、1からのインデックス列を追加できる。
上記の実行で、次のように「カスタム」フィールドにTableが追加される。
後述で確認するが、このTableは、「ファイルの変換」フィールドにあるTableにインデックス(行位置に該当)が追加されたものとなる。
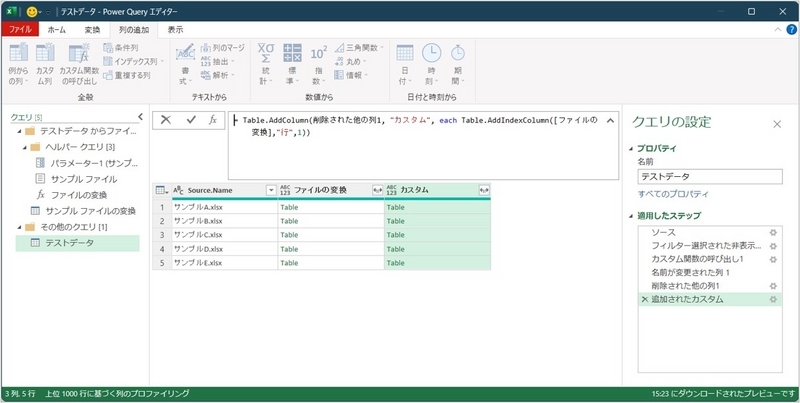
一旦余分なテーブルを削除(「ファイルの変換」の削除)
「ファイルの変換」フィールドを選択して、削除する。
Table.AddIndexColumn関数は、元のTableに、インデックス列を追加したTableのため、元のTableは不要。
「カスタム」フィールドのTableを展開
余分なテーブルを削除できたら、次のように「カスタム」フィールドを展開する(タイトルの右側の展開ボタンのクリック)。
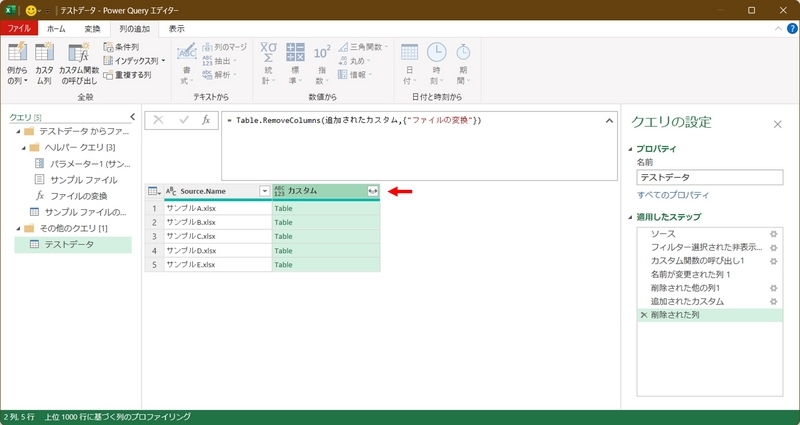
なお、展開の設定は、次のようにする。
・「すべての列の選択」のチェックをつける。
・「元の列名をプレフィックスとして使用します」のチェックを外す。
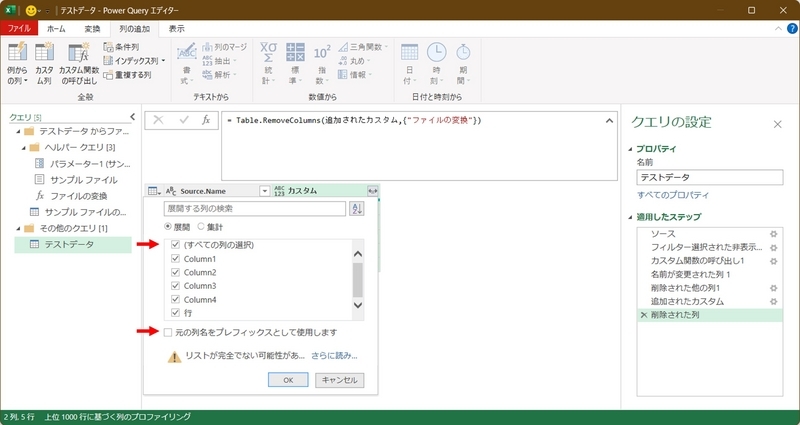
上記の実行で、ファイル毎に行の連番が付与された状態となる。
冒頭の「データの結合と変換」を実行後の状態と比較すると違いが把握できると思う。
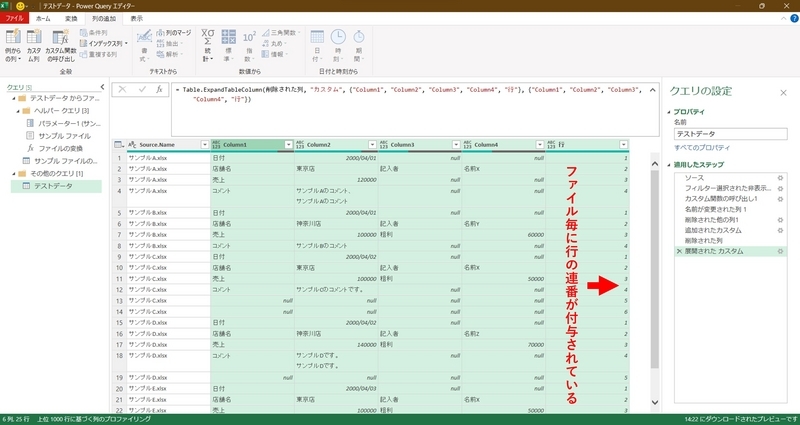
「その他の列のピボット解除」
Excelシート1枚につき、1レコードとなるようにするため、一旦、「列のピボット解除」をしてから「列のピボット」をする(現在の状態から直接1レコードに変換ができないため)。
具体的には、「Souce.Name」および「行」フィールドを選択し、「その他の列のピボット解除」をクリックする。
この理由は、現在のシートをピボットされた表とみなした場合、「Souce.Name」および「行」フィールドが、ピボットの行フィールドに該当するので、それ以外をピボット解除するためです。
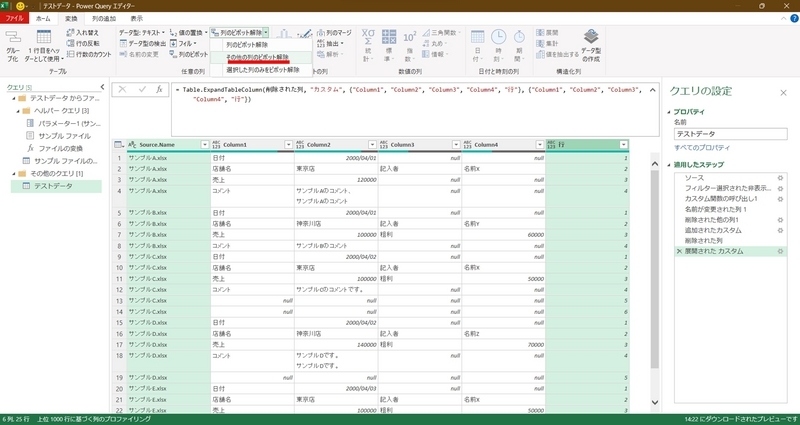
上記の結果、次のように値列が1列になる。列の情報に該当する情報も1列になっている(事例では、「属性」フィールドが作成され、その値にColumn1~Column4が入力されている)。
また、この段階でデータのないNullは削除され、以下情報が縦方向に抽出できている。
・Souce.Name(ファイル名)
・行(行番号)
・属性(列位置)
・値(セルの内容)
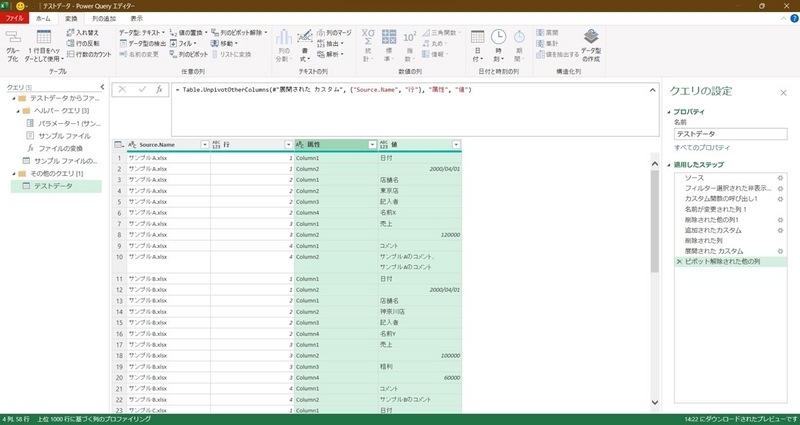
行と列の値を結合
パワークエリのピボットでは、列フィールドは1つしか設定できない。そのため、次のピボット処理で、Excelシート1枚につき、1レコードとするため、行と列の値を結合する(〇行△列という情報にするイメージ)。
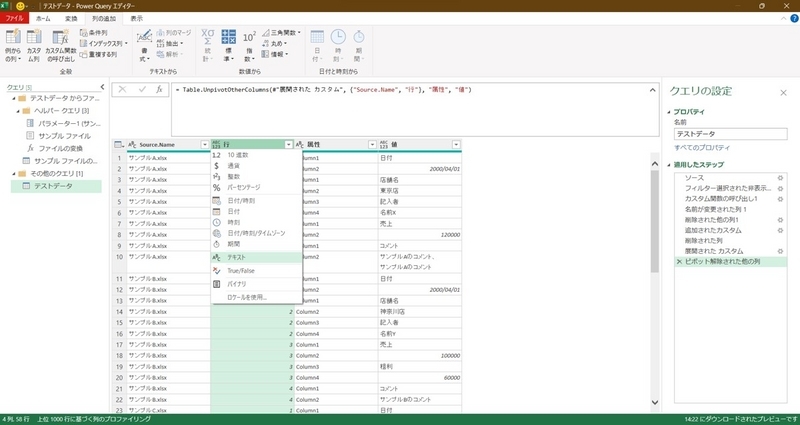
具体的には、テキスト結合時に数値型はエラーとなるため、「行」フィールドのデータ型をテキスト型に変換する。
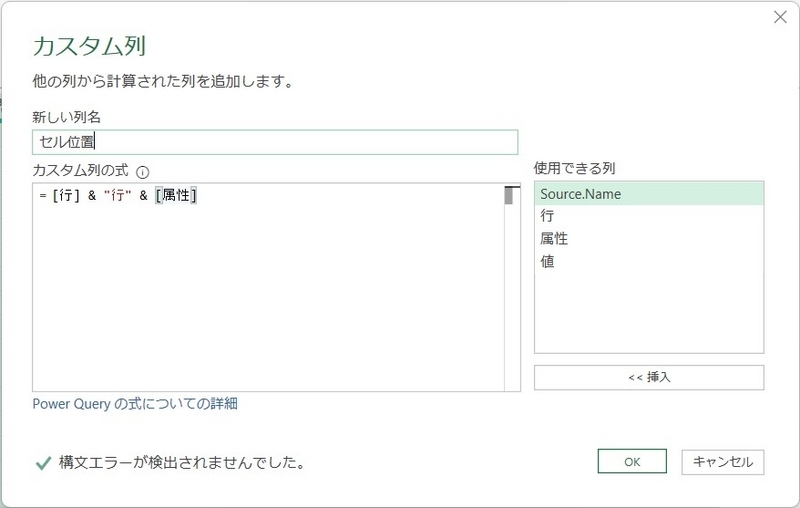
上記設定後、カスタム列の追加で次の数式を入力する。事例では、新しい列名を「セル位置」としている。
[行] & "行" & [属性]
なお、事前に「行」フィールドのデータ型をテキストに変換しないのであれば、Text.From関数を利用して以下でもよい。
Text.From([行]) & "行" & [属性]
上記の結果、「行」と「属性」フィールドの値が結合され、「セル位置」フィールドが追加される。
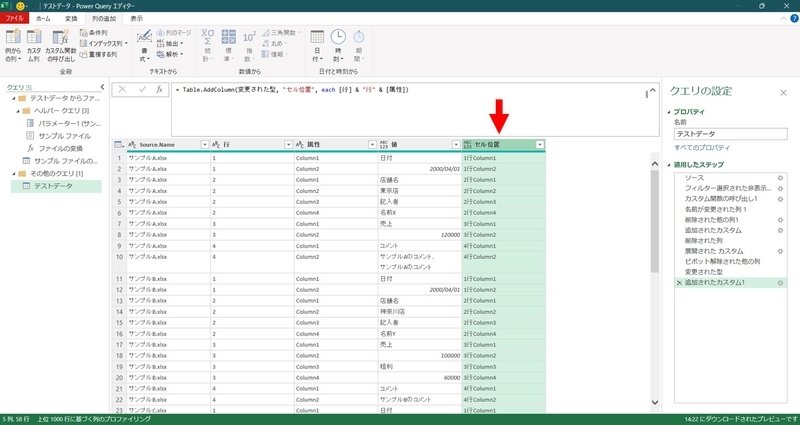
余分な「行」と「属性」フィールドの削除
「セル位置」フィールドに行と列の情報があるので、「行」と「属性」フィールドの削除。
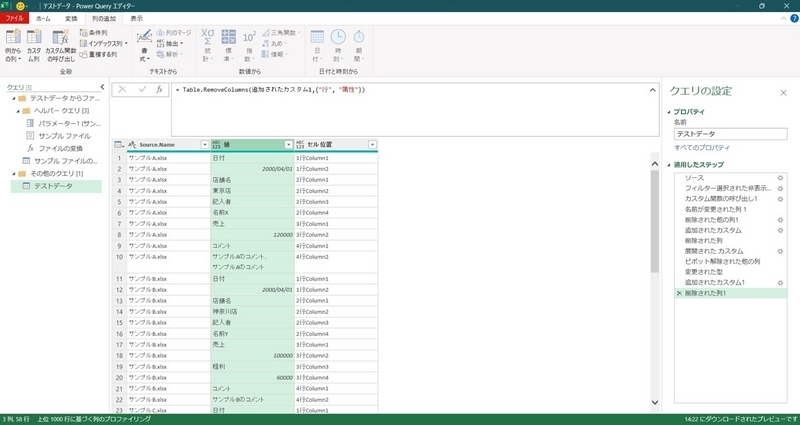
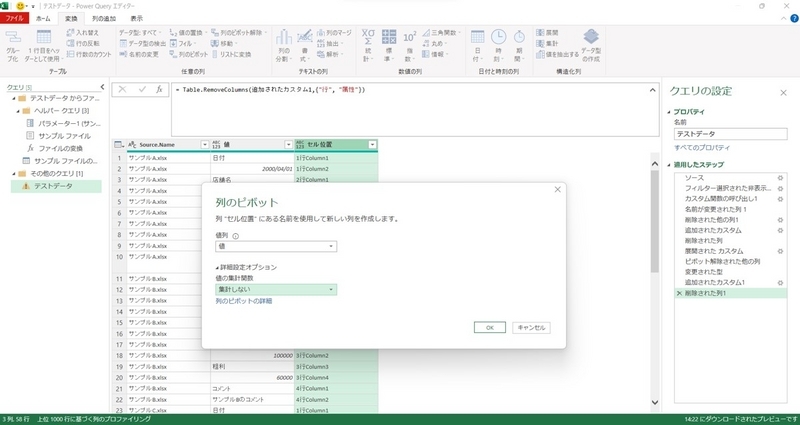
「セル位置」を選択して「列のピボット」
「セル位置」を選択して「列のピボット」をクリックする。なお、値列は「値」、値の集計関数は「集計しない」に設定する。
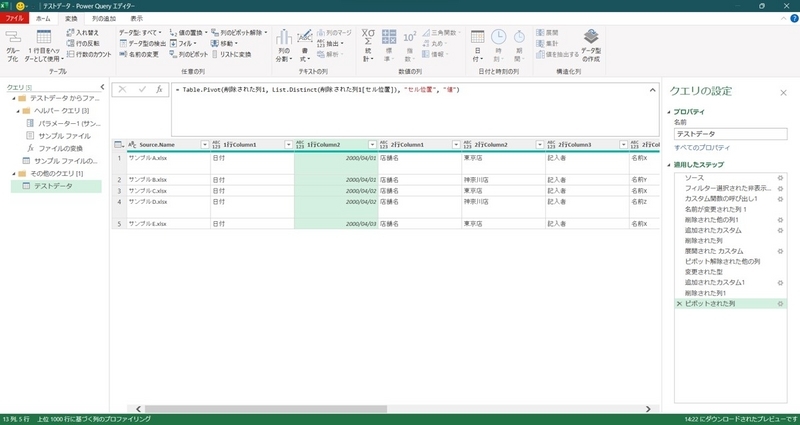
上記の結果、次のようにExcelシート1枚につき、1レコードのアウトプットができる。
以降は、PowerQueryの機能で項目名の修正や、不要なデータの削除等をして必要なアウトプットに整える。
補足説明
Table.AddIndexColumn関数について
その他の方法
Power Query単独で実行する方法は、目的によるが、Excelシートのレイアウトにより設定が手間となることもある。その他の方法としてVBAも解決手段の選択肢となります。
Excelで複数ブックのデータ(単票)を一覧表にまとめる方法にはいくつかの選択肢があるので以下に対応例をまとめました。
以上、Power Queryで、列のピボット解除を活用して「単票形式のExcelシートからセルの値を抽出」の備忘録でした。