Power Query(パワークエリ)に、Excelの数式でいうCOUNTIF関数がありません。
そのため、名簿の名寄せなどで各行の値の重複を数えたいときに悩んだので解決方法のメモ。
当該行にあるデータが列全体で何件あるかをカウントしたい場合、良さそうな方法は次の2つです。
- 「グループ化」を使う方法
- List.Count関数、List.FindText関数を組み合わせて使う方法
※ ただし、大量データには不向きな印象です。
今回は、「グループ化」を使う方法について説明します。
アウトプットイメージ
「名前」という列にある人と同じ名前の件数を「カウント」に表示するイメージ

作成手順
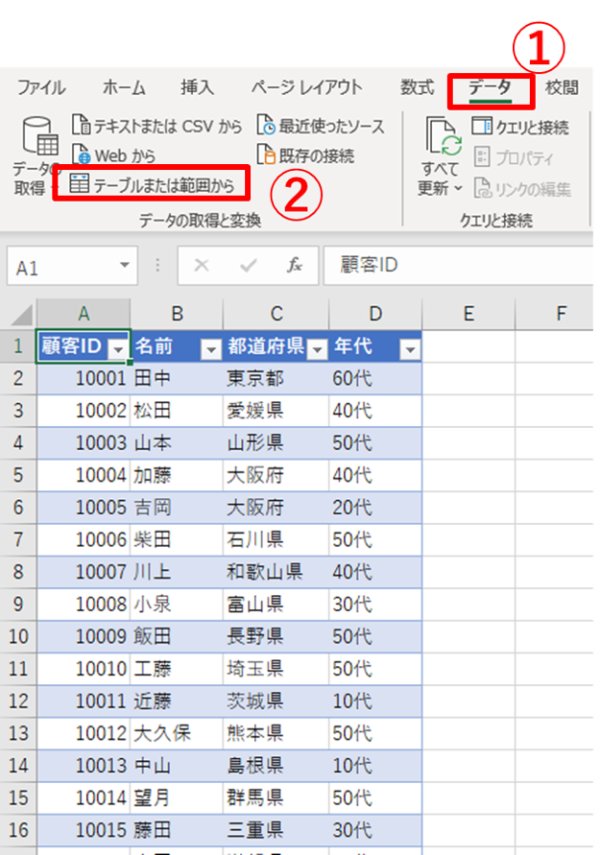
「テーブルまたは範囲から」で、クエリの作成
次のような、顧客ID、名前、都道府県、年代などのデータがあり、名寄せチェックのために「名前」の重複カウントをパワークエリで数えたい、とします。
「グループ化」をクリック
上記の実施後、次のクエリの画面が表示されるので「グループ化」をクリック

重複件数を集計したい「名前」でグループ化

ポイントは、次のとおり。
①「詳細設定」にする
②重複件数を集計したい列を選択
③「行数のカウント」とする。「新しい列名」は適当な名前で可。
④「すべての行」という項目を追加する。こちらも「新しい列名」は適当な名前で可。
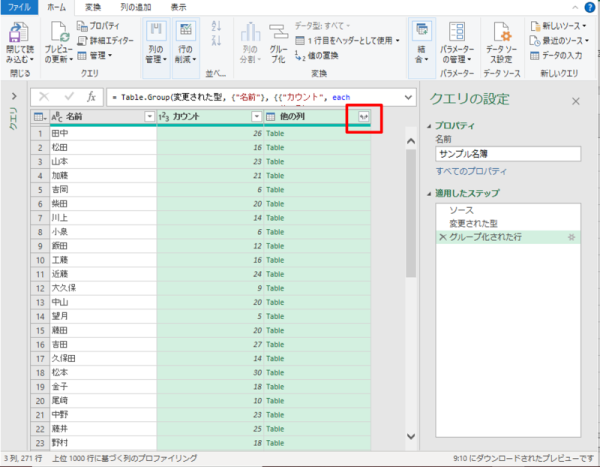
Tableを展開する。
グループ化した列(今回は「名前」という列)で、レコードの重複数が計算される。
今回、実施したいことは、レコードの重複数を元のデータに付与したいので、赤枠の箇所のボタン(データを展開)をクリックする。
次のように元の列名が表示される。グループ化に使用した「名前」の列は既にあるので、今回はチェックを外す。
*チェックを外さない場合は、同じデータの列ができるだけ。

(補足)「元の列名をプレフィックスとして使用します」のチェックを外した方が、元の列名になるので良い。今回の場合でいえば、「他の列.顧客ID」という列名か、「顧客ID」という列名になるかの違いです。
すると、レコードの重複数を含めた一覧が作成できる。

ただし、上記はグループ化した順番の一覧。
もし顧客IDなどの並び替えの基準があるデータなら、次のように並び替えると元データにレコードの重複数を含めた一覧ができる。

他の方法との違い
List.Count関数とList.FindText関数の組み合わせとの違い
現状のPower Query(パワークエリ)で、各行の値の重複件数を数える方法は「グループ化」が最適と思われる。
List.Count関数、List.FindText関数を組み合わせて使う方法は、処理時間が異常に長くなり、大量データには不向きな印象。
(印象でしかないが、Excelで大量データ時にするCOUNTIF関数と同様な処理を思わせる)
なお、今回はテーブルを展開したが、重複件数のクエリと元データのクエリを2つ作成し、マージする方法もある。グループ化した重複件数のクエリ結果自体をアウトプットとして使用する場合は、マージする方法が良さそうです。
特定の列と同じ値の列の個数を行ごとにカウントする方法
「当該行にあるデータが列全体で何件あるかをカウント」ではなく、「特定の列と同じ値の列の個数を行ごとにカウントする方法」の場合は次の方法です。
参考情報
サンプルデータ
上記の記事をもとに作成したサンプルファイルを以下で公開しています。実際のファイルで確認したい場合はご覧ください。
データの加工・抽出、管理の操作事例
データの加工・抽出、管理の操作事例を以下にまとめています。
以上、Power QueryでExcelのCOUNTIF関数のように、各行の値の重複を数える方法でした。
なお、パワークエリについては、次の書籍で何ができるのか全体像が理解できると思います。

パワークエリがわかると、データ集計業務の効率化が図れます。